


Decision Tree belongs to the family of supervised learning algorithms that is mostly used to solve the problems of classification but can also be used for regression. Decision trees can work with both categorical and continuous variables. The general idea behind Decision tree is to build a model that can be used predict the value of target variable while inferring the historical data.
To understand Decision tree is simpler than other machine learning algorithms as it simple mimics the human thinking while segregating the data. Decision trees actually let us see the logic used behind the final model.
For example if we are classifying repayment of bank loans, the decision tree may look like;
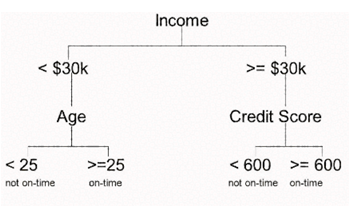
. Types of Decision trees: Decision trees are also known by the name CART (Classification and Regression Tree).
⦁ Categorical Variable Decision Tree: Decision tree which has categorical target variable are known as Categorical Variable Decision Tree. E.G. in case we want to predict Default/Non-Default output variable.
⦁ Continuous Variable Decision Tree: Decision Tree which has continuous target variable is known as Continuous Variable Decision Tree.
Important terminologies used in decision tree:

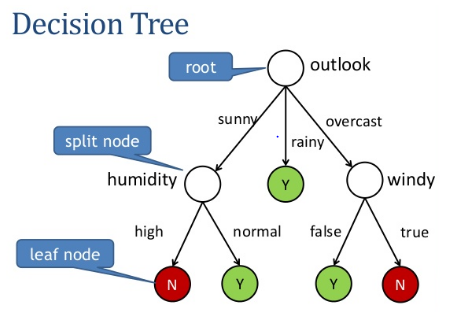
Root Node: The topmost decision node in a tree which corresponds to the best predictor called root node.
Split/Decision Node: The split node divides a sub node into two or more nodes also known as decision node
Leaf Node: Nodes that do not split are known as leaf node or Terminal node
Pruning: When we remove sub-nodes of a decision node, this process is called pruning. You can say opposite process of splitting.
Branch/Sub Tree: A sub section of entire tree is called branch or sub-tree
Parent/Child Node: A node, which is divided into sub-nodes is called parent node of sub-nodes whereas sub-nodes are the child of parent node.
How Decision tree works:
Decision tree uses multiple algorithms to decide on the split of a parent node into two or more child nodes. The split of parent node should result into increase in the homogeneity of data in child node. Decision tree tries to split the data based on all the available variables and selects the split which result into most homogeneous child nodes.
Classification Tree Split:
Gini Index: It’s a measure of node purity. If the Gini index takes on a smaller value, it suggests that the node is pure. For a split to take place, the Gini index for a child node should be less than that for the parent node.
Entropy – Entropy is a measure of node impurity. Entropy is maximum at p = 0.5. The entropy is minimum when the probability is 0 or 1.
Chi-Square: It is an algorithm to find out the statistical significance of the differences between sub-nodes and parent node.
Regression Tree Split:
In regression trees (where the output is predicted using the mean of observations in the terminal nodes), the splitting decision is based on minimizing RSS. The variable which leads to the greatest possible reduction in RSS is chosen as the root node. The tree splitting takes a top-down greedy approach, also known as recursive binary splitting. We call it “greedy” because the algorithm cares to make the best split at the current step rather than saving a split for better results on future nodes.
Advantages:
⦁ Easy to understand
⦁ Useful in data exploration
⦁ Less data cleaning required
⦁ Data type is not a constrain
⦁ Non Parametric
















{kind=link}